

درباره فایل Robots.txt بیشتر بدانید
یکی از ساده ترین فایل های یک وب سایت فایل Robots.txt است، اما میتواند به سادگی باعث ایجاد مشکل و خرابی می شود. اگر تنها یک کاراکتر خارج از مکان درست خود باشد، میتواند برای سئو مشکل ایجاد کند و از دسترسی موتورهای جستجو به مطالب مهم سایت جلوگیری کند.
به همین دلیل است که تصورات اشتباه درباره Robots.txt بسیار رایج است. حتی در میان متخصصان با تجربه سئو.
در این مقاله یاد خواهید گرفت:
- فایل Robots.txt چیست
- txt به چه شکل است
- User-agents و دستورالعمل های فایل ربات
- آیا به فایل ربات نیاز داریم
- چگونه فایل txt وب سایت خود را پیدا کنید
- نحوه ی ایجاد فایل ربات TXT
- بهترین روش های ساخت ربات TXT
- مثال های از txt
- چگونگی بررسی و رسیدگی مشکلات بوجود آمده فایل ربات
فایل Robots.txt چیست؟
Robots.txt به موتورهای جستجو میگوید که به چه بخش هایی از سایت میتوانند وارد شوند و چه بخش هایی را نمیتوانند وارد شوند.
در درجه اول، تمام مطالبی که میخواهید از دسترسی موتورهای جستجو مثل گوگل خارج کنید را لیست میکند. همچنین میتوانید به برخی از موتورهای جستجو (نه گوگل) بگویید که چگونه میتوانند محتوای مجاز را کراول کنند.
جالب است بدانید که بیشتر موتورهای جستجو مطیع هستند. آنها عادت به شکستن راه ورود را ندارند در واقع میتوان گفت برخی تمایلی به برداشتن این قفل های مجازی ندارند که گوگل یکی از آن موتورهای جستجو نیست، آن از تمامی دستورالعمل های مربوط به فایل Robots.txt پیروی میکنند.
فقط این را بدانید که بعضی از موتورهای جستجو کاملا آن را نادیده می گیرند.
فایل Robots.txt چگونه ایجاد میشود؟
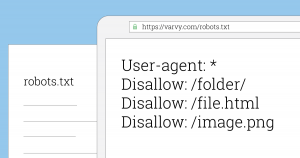
در اینجا فرمت اصلی یک فایل Robots.txt توضیح خواهم داد :
اگر تا بحال فایلی مانند این ندیده اید، ممکن است کمی ترسناک به نظر برسد. اگرچه دستورات نوشتاری (syntax) آن کاملا ساده است. به طور خلاصه شما قوانین و قواعد را به ربات ها با تعیین مرورگر آنها و دستورالعمل های مربوط به آن اختصاص می دهید.
بیاید با جزئیات بیشتری به بررسی این دو مؤلفه بپردازیم.
User-agents
هر موتور جستجو خود را با یک User-agants متفاوت مشخص میکند. شما میتوانید دستورالعمل های سفارشی برای هر یک از این موارد را در فایل Robots.txt خود تنظیم کنید. تعداد زیادی User-agents وجود دارد، اما در اینجا چند مورد مفید برای سئو را معرفی میکنیم:
- Google: Googlebot
- Google Images: Googlebot-Images
- Bing: Bingbot
- Yahoo: Slurp
- Baidu: Baiduspider
- DuckDuckGo: DuckDuckBot
نکته : حتما دقت کنید که همهی User-agent ها در فایل Robots.txt به حروف کوچک و بزرگ (case sesitive) حساس هستند.
همچنین می توانید از (*) ستاره برای اختصاص دستورالعمل ها به همه ی User-agent ها استفاده کنید.
به عنوان مثال، شما میخواهید همه ربات ها بجز Googlebot را از خزیدن یا کراول سایت خود مسدود کنید. در اینجا نحوه انجام آن را می بینید:
باید بدانید که فایل Robots.txt میتواند دستور العمل ها را برای هر تعداد دلخواه User-agents در نظر بگیرد. به این صورت، هر بار که User-agent جدیدی را اعلام کنید، آنچه که مربوط به قبل بوده را در نظر نمیگیرد (مانند یک صفحه سفید عمل میکند). به عبارت دیگر اگر برای چندین User-agent دستورالعمل اضافه کنید، دستورالعمل های اعلام شده برای User-agent اول، در مورد دوم، یا سوم، یا چهارم و الی آخر اعمال نمیشود.
استثناء آن قانون در مواردی است که شما بیش از یک بار همان User-agent را اعلام میکند. در این حالت، همه ی دستورالعمل های مربوطه انجام و دنبال میشوند.
خوب است بدانید که خزنده ها فقط قوانینی که تحت عنوان (User-agents) اعلام شده و به طور دقیق در مورد آنها اعمال میشود را دنبال می کند. به همین دلیل فایل Robots.txt در بالا، همه ی ربات ها بجز Googlebot (و سایر ربات های گوگل) را از خزیدن سایت ممنوع کرده است. Googlebot اعلان آن User-agent که مرتبه کمتری دارد را رد میکند.
دستورالعمل های فایل ربات TXT
دستورالعمل ها قوانین و قواعد برای User-agent ها هستند که شما می خواهید از این دستورالعمل ها پیروی کنند.
دستورالعمل های پشتیبانی شده
در اینجا دستورالعمل هایی که در حال حاضر گوگل از آنها پشتیبانی میکند، به همراه کاربردهای آن ها وجود دارد.

Disallow
از این دستور برای راهنمایی موتورهای جستجو استفاده می شود تا به فایل ها و صفحاتی که در یک مسیر خاص وجود دارند دسترسی پیدا نکنند. برای مثال، اگر می خواهید همه ی موتورهای جستجو را از دسترسی به وبلاگ و همه ی پست های آن مسدود کنید، فایل Robots.txt شما به این شکل باید باشد:
نکته: اگر نتوانید مسیری را بعد از دستور disallow تعیین کنید، موتورهای جستجو آن را نادیده میگیرند.
Allow
این دستور به به موتورهای جستجو اجازه میدهد تا یک زیرشاخه یا یک صفحه را کراول کنند، حتی فایل های غیرمجاز. برای مثال، اگر میخواهید از دسترسی موتورهای جستجو به هر پست در وبلاگ خود بجز یک مورد آن جلوگیری کنید، فایل Robots.txt شما به این گونه خواهد بود:
در این مثال، موتورهای جستجو به /blog/allowed-post دسترسی دارند. اما به این پست ها دسترسی ندارند:
/blog/another-post
/blog/yet-another-post
/blog/download-me.pdf
نکته ۱ : گوگل و Bing هر دو این دستور را پشتیبانی میکنند.
نکته ۲ : مانند دستور Disallow، اگر نتوانید مسیری را پس از دستور Allow تعریف کنید، موتورهای جستجو آنرا نادیده میگیرند.
باید بدانید که دستورهای Disallow و Allow به راحتی با یکدیگر تداخل ایجاد میکنند. در مثال زیر، ما دسترسی به /blog/ را ممنوع یا همان Disallow کردیم، و به /blog اجازه دسترسی (Allow) داده ایم.
در این مورد، بنظر میرسد آدرس /blog/post-title/ هم اجازه دسترسی (Allow) و هم عدم دسترسی (Disallow) دارد. پس کدام یک برنده است؟
برای گوگل و Bing، قاعده به این صورت است که دستوری که بیشترین تعداد کاراکتر را داشته باشد برنده می شود. در اینجا، دستور disallow برنده است.
Disallow: /blog/ ۶ کاراکتر
Allow: /blog ۵ کاراکتر
اگر طول دستورات allow و disallow یکسان بود، دستوری که کمترین محدودیت را دارد برنده است. در این حالت، دستور allow می باشد.
نکته: در اینجا، /blog (بدون / در انتهای آن) هم قابل دسترسی و قابل کروال شدن است.
نکته مهم: این موضوع فقط در مورد گوگل و Bing اتفاق می افتد. موتورهای جستجو دیگر به اولین دستور منطبق نگاه می کنند. پس در این حالت، دستور disallow میباشد.
Sitemap
با استفاده از این دستور مکان سایت مپ (sitemap) سایت خود را برای موتورهای جستجو مشخص کنید. (اگر درباره ی سایت مپ (sitemap) نمیدانید، آن شامل صفحاتی است که میخواهید موتورهای جستجو کراول و ایندکس کنند.)
در اینجا نمونه ای از فایل Robots.txt که از دستور سایت مپ (sitemap) استفاده کرده است را آورده ایم:
شاید برایتان سوال باشد که چقدر مهم است که در فایل Robots.txt نقشه سایت یا همان sitemap را درج کنیم؟
اگر قبلا sitemap خود را در سرچ کنسول ثبت کرده اید، تا حدودی کار اضافی برای گوگل انجام داده اید. با این حال، این کار به دیگر موتورهای جستجو مانند Bing میگوید که کجا سایت مپ شما را پیدا کنند. بنابراین هنوز هم عمل خوبی است.
توجه داشته باشید که نیازی نیست هر بار برای هر user-agent دستور سایت مپ را تکرار کنید. این دستور فقط برای یک مورد صدق نمیکند. بنابراین بهتر است دستور سایت مپ را در ابتدا یا پایان فایل Robots.txt قرار دهید. مثلا: گوگل، یاهو، Bing، Ask از این دستور پشتیبانی می کنند.
نکته: می توانید هر تعداد sitemap که بخواهید در فایل robots.txt خود داشته باشید.

دستورهای غیر قابل پشتیبانی
در این بخش دستورالعمل هایی که (بعضی از آنها از نظر فنی وجود ندارد) توسط گوگل دیگر پشتیبانی نمیشود را می بینیم.
Crawl-delay
پیش از این شما میتوانستید از این دستور برای مشخص کردن زمان تاخیر خزنده در ثانیه استفاده کنید. برای مثال، اگر میخواستید Googlebot پس از هر عمل خزیدن یا کراول ۵ ثانیه صبر کند، شما crawl-delay را روی ۵ مثل مثال زیر تنظیم میکردید:
گوگل دیگر از این دستور پشتیبانی نمیکند، اما Bing و Yandex این کار را انجام میدهند.
گفته میشود، هنگام تنظیم این دستورالعمل دقت کنید، به خصوص اگر سایت بزرگی دارید.
اگر crawl-delay را روی ۵ ثانیه تنظیم کنید، شما ربات ها را محدود کردید تا حداکثر ۱۷۲۸۰ آدرس اینترنتی را در یک روز کراول کنند. که این برای سایت هایی که میلیون ها صفحه داشته باشد، اصلا مفید نیست. اما در صورت داشتن یک وب سایت کوچک می توانید با این کار پهنای باند (bandwidth) را ذخیره کنید.
Noindex
این دستورالعمل هرگز توسط گوگل به طور رسمی پشتیبانی نمیشد. با این حال تا همین اواخر، تصور میشد که گوگل تعدادی “کد که برای قوانین پشتیبانی نشده و منتشر نشده (مثل noindex) بکار می رود” داشت.
بنابراین اگر میخواهید از ایندکس کردن همه ی پست های وبلاگ خود در گوگل جلوگیری کنید، میتوانید از این دستورالعمل استفاده کنید.
با این حال، در ۱ سپتامبر ۲۰۱۹، گوگل به طور واضح اعلام کرد که این دستورالعمل پشتیبانی نمیشود.
اگر میخواهید دسترسی یک صفحه یا فایل های خود را از موتورهای جستجو ببندید، به جای آن از meta robots tag یا x-robots HTTP header استفاده کنید.
Nofollow
دستور nofollow نیز دستور دیگری است که گوگل هیچ وقت به طور رسمی از آن پشتیبانی نکرده است. این دستور بدین منظور استفاده می شد که برای موتورهای جستجو تعیین میکرد که لینک های صفحات و فایل های مسیر مشخص شده را دنبال نکنند. به عنوان مثال، اگر میخواستید جلوی گوگل را از دنبال کردن همه ی لینک های موجود در وبلاگ خود را بگیرید، باید از دستور زیر استفاده میکردید:
گوگل در تاریخ ۱ سپتامبر ۲۰۱۹، اعلام کرد که این دستور به طور رسمی پشتیبانی نمیشود. اگر الان میخواهید همه ی لینک های یک صفحه را nofollow کنید، باید از robots meta tag یا x-robots header استفاده کنید. همچنین اگر می خواهید گوگل لینک خاصی را در یک صفحه دنبال نکند، باید از ویژگی rel=”nofollow” در تگ لینک خود استفاده کنید.
آیا به فایل robots.txt نیاز دارید؟
داشتن فایل robots.txt برای بسیاری از وب سایت ها، به ویژه برای سایت های کوچکتر، خیلی مهم نیست.
در واقع، هیچ دلیل خوبی برای نداشتن فایل robots.txt وجود ندارد. این فایل به شما این امکان را میدهد تا کنترل بیشتری بر روی موتورهای جستجو داشته باشید، که به کدام قسمت از وب سایت شما وارد شوند یا وارد نشوند. و این موضوع میتواند در بعضی موارد به شما کمک کند مثل :
- جلوگیری از کراول کردن محتوای تکراری
- خصوصی نگه داشتن بخش هایی از وب سایت (مثل مرحله بندی سایت)
- جلوگیری از کراول کردن صفحات نتایج جستجوی داخلی
- جلوگیری از ایجاد بار سنگین بر روی سرور
- جلوگیری گوگل از اتلاف “crawl budget” (جلوگیری از به هدر رفتن زمان سپری شده در هنگام بازدید وب سایت توسط ربات ها)
- جلوگیری از نمایش تصاویر، فیلم ها و فایل های منبع در نتایج جستجوی گوگل.
توجه داشته باشید که اگر گوگل صفحاتی که در فایل robots.txt مسدوده شده است را ایندکس نمیکند، هیچ تضمینی برای ممنوع شدن از نتایج جستجو در فایل robots.txt وجود ندارد.
همانطور که گوگل میگوید، اگر محتوایی به دیگر مکان های از وب لینک داده شود، ممکن است همچنان در نتایج جستجوی گوگل ظاهر شود.
چگونه فایل robots.txt خود را پیدا کنیم؟
اگر در حال حاضر یک فایل robots.txt در وب سایت خود دارید، در domain.com/robots.txt قابل دسترسی خواهد بود. در مرورگر خود به این آدرس بروید. اگر چیزی شبیه این را می بینید، پس فایل robots.txt دارید.
نحوه ایجاد فایل robots.txt
اگر در حال حاضر فایل robots.txt ندارید، ایجاد آن کار آسانی است. برای شروع کافی است که یک سند خالی با فرمت .txt را باز کنید و تایپ دستورالعمل ها را شروع کنید. به عنوان مثال، اگر می خواهید دسترسی همه ی موتورهای جستجو را از خزیدن یا کراول کردن دایرکتوری /admin/ ببندید، چیزی شبیه به این را خواهید داشت:
به این کار ادامه دهید، تا زمانی که تمام دستوراتی که میخواستید را نوشته باشید. سپس فایل خود را با نام “robots.txt” ذخیره کنید.
از طرف دیگر شما می توانید از یک ابزار robots.txt generator مثل این استفاده کنید.
مزیت استفاده از این نوع ابزارها این است که خطاهای نوشتاری (syntax) را به حداقل می رساند. این مزیت خوبی است به این خاطر که یک اشتباه می تواند منجر به ایجاد مشکل برای سئو وب سایت شما شود. بنابراین باید خطرات احتمالی را بپذیرید.
نقطه ضعف این ابزار ایجاد محدودیت از نظر شخصی سازی می باشد.
فایل robots.txt را باید در کجا قرار دهیم؟
فایل robots.txt خود را در زیر دامنه ی (subdomain) دایرکتوری اصلی (root directory) باید قرار دهید. به عنوان مثال برای کنترل رفتار کراولر یا خزنده در domain.com فایل robots.txt باید در آدرس domain.com/robots.txt در دسترس باشد.
اگر می خواهید خزیدن یا کراول کردن روی یک ساب دامین مانند blog.domain.com را کنترل کنید، باید فایل robots.txt در blog.domain.com/robots.txt در دسترس باشد.
بهترین روش های Robots.txt
این موارد را به خاطر داشته باشید تا از اشتباهات رایج خودداری کنید.
برای هر دستور یک خط در نظر بگیرید
هر دستور باید در یک خط جدید قرار گیرد. در غیر این صورت، موتورهای جستجو را دچار سردرگمی میکند.
نمونه اشتباه:
نمونه صحیح:
استفاده از wildcards برای ساده کردن دستورالعمل ها
نه تنها می توانید از وایلد کارد (*) برای اعمال دستورها برای همه ی user-agent ها استفاده کنید، بلکه برای آدرس هایی که والد یکسان دارند و می توان آنها را باهم تطبیق داد به هنگام اعلام دستور استفاده کنید. برای مثال، اگر شما می خواهید از دسترسی موتورهای جستجو به آدرس های طبقه بندی شده ی محصول در سایت خود جلوگیری کنید، می توانید این موارد را به این طریق لیست کنید:
اما این کار خیلی کارآمد نیست. بهتر است با استفاده از وایلدکارد (wildcard) کار را ساده تر کنید. مانند زیر:
این مثال موتورهای جستجو را از کراول کردن همه ی آدرس هایی که در پوشه ی زیر /product/ قرار دارد و حاوی یک علامت سوال هستند را جلوگیری می کند. به عبارت دیگر، هر آدرس پارامتری کتگوری محصول.
استفاده از “$” برای مشخص کردن پایان URL
نماد “$” را پایان URL بنویسید تا انتهای آدرس مشخص شود. به عنوان مثال، اگر می خواهید موتورهای جستجو به تمام فایل های .pdf سایت شما دسترسی نداشته باشند، فایل robots.txt شما باید این گونه باشد:
در این مثال، موتورهای جستجو نمی توانند به آدرس هایی که به .pdf ختم می شوند، دسترسی داشته باشند. این بدین معنی است که آنها به /file.pdf دسترسی ندارند، اما می توانند به /file.pdf?id=68937586 دسترسی پیدا کنند. به این دلیل که این آدرس به “.pdf” ختم نمی شود.
از هر user-agent فقط یک بار استفاده کنید
اگر یک user-agent را چندین بار استفاده کنید، گوگل توجهی نمی کند. گوگل صرفا همه ی دستورات و قوانین از اعلان های مختلف را در یکی ترکیب می کند و همه ی آنها را دنبال می کند. برای مثال، اگر در فایل robots.txt خود user-agents و دستورات زیر را دارید…
…Googlebot نمی تواند هیچ یک از این پوشه ها را کراول کند.
با توجه به این گفته، کاملا معقول است که هر user-agent را فقط یکبار صدا کنیم زیرا کمتر باعث سردرگمی می شود. به عبارت دیگر، اگر دستورات را مرتب و تمیز بنویسید، احتمال اینکه اشتباهی رخ دهد بسیار کمتر است.
استفاده از دستورات مشخص برای جلوگیری از خطاهای غیر عمدی
عدم استفاده از دستورالعمل های مشخص و صحیح به هنگام تنظیم دستورات می تواند منجر به اشتباهاتی شود به راحتی باعث تاثیر فاجعه آمیزی بر سئوی سایت شما داشته باشند. به عنوان مثال، فرض می کنیم که شما یک سایت چند زبانه دارید و در حال حاضر دارید روی نسخه زبان آلمانی کار می کنید که تحت زیر دایرکتوری /de/ قرار دارد.
از آنجا که هنوز کاملا آماد نیست، شما می خواهید که از دسترسی موتورهای جستجو جلوگیری کنید.
فایل robots.txt زیر مانع دسترسی موتورهای جستجو به آن پوشه و همه ی موارد داخل آن می شود:
اما مانع از خزیدن یا کراول کردن موتورهای جستجو در صفحات و یا فایل هایی که با /de شروع می شوند نیز می شود.
برای مثال:
/designer-dresses/
/delivery-information.html
/Depeche-mode/t-shirts/
/definitely-not-for-public-viewing.pdf
در این مثال، راه حل بسیار ساده است: در انتها یک اسلش اضافه کنید.
استفاده از کامنت در فایل robots.txt برای توضیحات بیشتر به انسان
گذاشتن کامنت به توسعه دهندگان (developers) کمک می کند تا دستورات فایل robots.txt برای آنها واضح و مشخص باشد. حتی این کامنت ها در آینده می توان برای خود شما نیز کمک کننده باشد.
برای درج کامنت باید ابتدای آن را با یک (#) شروع کنید.
کراولر ها یا خزنده ها هر آنچه در نوشته هایی که با # شروع شده باشند را نادیده می گیرد.
استفاده از یک فایل robots.txt جداگانه برای هر زیر دامنه (subdomain)
Robots.txt رفتار کراولر یا خزنده در هر زیر دامنه (subdomain) را فقط وقتی خودش میزبان باشد کنترل می کند. اگر می خواهید رفتار کراولر روی هر زیر دامنه (subdomain) را کنترل کنید، برای هر کدام یک فایل robots.txt جداگانه نیاز دارید.
به عنوان مثال، اگر سایت اصلی شما در domain.com و وبلاگ شما در bolg.domain.com قرار دارد، پس شما به دوتا فایل robots.txt احتیاج دارید. یکی از آنها باید در دایرکتوری root از دامنه اصلی قرار بگیرد و دیگری دایرکتوری root وبلاگ قرار بگیرد.
مثال هایی از robots.txt
در زیر چند نمونه از فایل های robots.txt آورده شده است. این نمونه ها عمدتا برای الگو گرفتن است اما اگر اتفاقی یکی از این نمونه ها با آن چیزی که شما نیاز دارید مطابقت داشت، می توانید آن را در یک فایل متنی (text document) گپی کنید و آن را با نام “robots.txt” ذخیره کنید و در آخر در دایرکتوری مناسب بارگذاری کنید.
دسترسی همه جانبه برای همه ی ربات ها
نکته: عدم اعلام یک URL پس از یک دستورالعمل، مانع اجرای این دستور می شود یا به اصطلاح از کار می اندازد. به عبارت دیگر موتورهای جستجو آن را نادیده می گیرند. به همین دلیل این دستور disallow هیچ تاثیری در سایت ندارد. موتورهای جستجو هنوز می تواند همه صفحات و فایل ها را کراول کنند.
عدم دسترسی به همه ربات ها
مسدود کردن یک ساب دایرکتوری برای همه ربات ها
مسدود کردن یک ساب دایرکتوری برای همه ربات ها (بجز یک فایل)
مسدود کردن یک فایل برای همه ربات ها
مسدود کردن یک نوع فایل (مثل PDF) برای همه ربات ها
مسدود کردن URL هایی پارامتری فقط برای Googlebot
چگونگی بررسی و رسیدگی مشکلات بوجود آمده Robots.txt
اشتباهات robots.txt می تواند به راحتی درون اینترنت منتشر شود، بنابراین باید حواسمان کاملا به این مسائل باشد.
برای این کار، مرتبا باید موارد مربوط به robots.txt را در قسمت گزارش “Coverage” سرچ کنسول بررسی کنید. در زیر برخی از خطاهایی که ممکن است مشاهده کنید، منظور آنها و نحوه ی رفع آنها آورده شده است.
آیا نیاز به بررسی خطاهای مربوط به یک صفحه خاص را دارید؟
آدرس موردنظر خود را در ابزار Google`s URL Inspection در سرچ کنسول وارد کنید. اگر توسط robots.txt مسدود شده است، باید چیزی شبیه به این را مشاهده کنید:
مسدود شدن URL های ثبت شده توسط robots.txt
این بدین معنی است که حداقل یکی از آدرس های ثبت شده در sitemap توسط robots.txt مسدود شده است.
اگر Sitemap خود را به درستی ایجاد کرده اید و صفحات ریدایرکت شده، noindexed و کنونیکال را مسثتنی قرار داده اید، هیچ یک از صفحات ثبت شده نباید توسط robots.txt مسدود شود. اگر هم وجود دارد، بررسی کنید که کدام صفحات اثر گذاشته است، سپس فایل robots.txt خود را مطابق با آن تنظیم کنید تا آن صفحه از بلاک خارج شود.
شما می توانید از Google`s robots.txt tester استفاده کنید تا ببینید کدام دستور محتوا را مسدود کرده است. فقط در هنگام انجام این کار مراقب باشید. ممکن است به راحتی اشتباهی صورت بگیرد و این باعث اثر گذاشتن روی دیگر صفحات و فایل ها شود.
بلاک شده توسط robots.txt
این بدین معنی است که شما محتوایی دارید که توسط robots.txt مسدود شده است که در حال حاضر در گوگل ایندکس نمی شوند.
اگر این محتوا مهم است و باید ایندکس شود، مسدود سازی خزنده یا کراولر را از robots.txt حذف کنید. (همچنین لازم است اطمنیان حاصل کنید که محتوا noindexed نباشد). اگر شما محتوا را در robots.txt با قصد جلوگیری از ایندکس شدن در گوگل مسدود کرده اید، باید از بلاک خارج کرده و به جای آن از robots meta tag یا x-robots-header استفاده کنید. این تنها راهی است که تضمین می کند گوگل این محتوا را ایندکس نمی کند.
نکته: حذف مسدود سازی خزنده یا کراولر وقتی قصد خارج کردن یک صفحه از نتایج گوگل را دارید بسیار مهم است. اگر این کار را انجام ندهید و گوگل تگ noindex یا HTTP header را مشاهده نکند، در این صورت همچنان ایندکس باقی خواهد ماند.
اگر چه توسط robots.txt بلاک شده ولی ایندکس شده
این بدین معنی است که برخی از محتواهایی که توسط robots.txt مسدود شده اند هنوز در گوگل ایندکس می شوند.
یک بار دیگر، اگر می خواهید این محتوا را از نتایج جستجوی گوگل حذف کنید، robots.txt راه حل مناسب و درستی نیست. شما باید مسدود سازی کراولر را برداشته و در عوض از meta robots tag یا x-robots-tag HTTP header استفاده کنید تا از ایندکس کردن جلوگیری کند.
اگر اشتباهی این محتوا را بلاک کرده اید و می خواهید در گوگل ایندکس شود، مسدود سازی کراولر را در robots.txt حذف کنید. این کار کمک می کند تا محتوای شما در نتایج گوگل دیده شود.
پرسش و پاسخ سوالات احتمالی درباره فایل ربات
در اینجا چند سوال متداولی وجود دارد که در مباحث بالا قرار نداشته است. اگر سوالی دارید که در مطالب بالا گفته نشده برای من کامنت بگذارید تا این بخش را بروز کنم.
حداکثر اندازه ی یک فایل robots.txt چقدر است؟
تقریبا ۵۰۰ کیلوبایت
فایل robots.txt در وردپرس کجاست؟
در همان مکانی که گفته شد: domain.com/robots.txt
چگونه فایل robots.txt را در وردپرس ویرایش کنم؟
یا به صورت دستی، یا با استفاده از پلاگین های موجود مثل Yoast یوآست که به شما این امکان را می دهد از بخش بک اند وردپرس فایل robots.txt را ویرایش کنید.
چه اتفاقی می افتاد اگر دسترسی به محتوای noindexed را در فایل robots.txt، ببندیم (disallow) ؟
گوگل هرگز دستور noindex را نمیبیند چون نمی تواند صفحه را کراول کند.
نتیجه نهایی
فایل robots.txt یک فایل ساده ولی در عین حال قدرتمنداست. از آن هوشمندانه استفاده کنید، تا تاثیر مثبتی بر سئو داشته باشد.
نوشته فایل Robots.txt چه تاثیری بر سئو دارد؟ اولین بار در سئو توسط علی حسینی. پدیدار شد.





